PA4 - Tiled Matrix Multiplication
Objective
Implement a tiled dense matrix multiplication routine using shared memory. Note: you will not need to transpose any matrix for PA4.
Instructions
Edit the code in the code tab to perform the following:
Allocate device memory
Copy host memory to device
Initialize work group dimensions
Invoke OpenCL kernel
Copy results from device to host
Deallocate device memory
Implement the matrix-matrix multiplication routine using shared memory and tiling
Files and Directories
Makefile: Automates the compilation and execution process for the project.
main.c: Source code for the tiled matrix multiplication using OpenCL.
Dataset/dataset_generator.py: Source code for generating random matrices.
kernel.cl: OpenCL kernel file for performing tiled matrix multiplication.
How to Compile
The main.c, kernel.cl files contains the code for the programming assignment. It can be run by typing make from the PA4 folder. It generates a solution output file.
How to Test
Use the make run command to test your program. here are a total of 11 tests on which your program will be evaluated for (functional) correctness. We will use the last test case (testcase 10) to verify if your programs meet the speedup requirements that you should get using shared memory. The timing requirements will only be strict enough to ensure students cannot submit PA3’s solution in PA4 and get credit.
Use the make time command to see timing details for your kernel. Your kernel must produce a time less than 43ms.
Dataset Generation (Optional)
The dataset required to test the program is already generated. If you are interested in how the dataset is generated please refer to the dataset_generator.py file in the Dataset folder. To recreate the dataset, run the dataset_generator.py file.
Submission
Submit the main.c and kernel.cl files on Gradescope. Preserve the file name and kernel file name as the kernel name is used to identify and time the kernel code. Gradescope will only accept 1 submission per hour. Please do not use Gradescope to time your code.
Grading
You will be graded on correctness (95pts) and on your time on a 1080ti. Times subtract from your correctness.
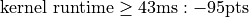

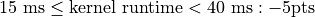
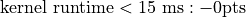
These times will be on the leaderboard
Optional
Like last PA, we have a optional section on the PA for bragging rights. A major point behind using OpenCL is applying the same kernel to many devices. So also on the leaderboard are three other devices (a CPU, a Google Pixel Fold’s GPU, and a Thundercomm Rubik Pi’s GPU):
Platform |
Device |
|---|---|
Intel® OpenCL |
Intel® Xeon® Platinum 8275CL |
Portable Computing Language |
NVIDIA GeForce GTX 1080 Ti |
Google Tensor |
Mali-G710 r0p0 |
Qualcomm Dragonwing™ |
Qualcomm Adreno™ 643 |
Good implementations may optimize for one device, great implementations will optimize for many devices that you are targeting for.
Hint 0: if you looked for “//@@ Hint”, you will find how to identify the platform and device name, in case that is useful for optimizing per device. Hint 1: You will not have access to the RubricPis and phones and the rate limit still applies on gradescope. What kind of optimizations can you do just without device access but with publically available information about the device? How do you reduce trial and error here?