PA3 - Matrix Multiplication
Objective
The purpose of this lab is to get you familiar with mapping computations onto the GPU and multi-dimensional local and global work sizes. You will implement transposed matrix multiplication by writing the GPU kernel code as well as the associated host code.
Instructions
Given matrices 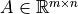 and
and 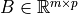 , compute
their product
, compute
their product 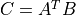 .
Recall that
.
Recall that 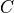 will be an
will be an 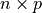 matrix that
can be computed with the following formula:
matrix that
can be computed with the following formula:
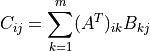
Where 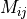 is the entry at the row
is the entry at the row 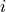 and
column
and
column 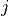 of matrix
of matrix 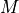 .
.
Edit the code to perform the following:
Set the dimensions of the result matrix
Create device buffers for the matrices
Copy host memory to device buffers
Create the kernel
Set up arguments for the kernel
Define local and global work sizes
Invoke OpenCL kernel
Copy result matrix from device to host
Release memory on device
Write the OpenCL kernels to perform matrix multiplication without coarsening, with row wise coarsening, and an optional kernel with your choice of optimizations
Instructions about where to place each part of the code is demarcated by the //@@ comment lines.
How to Compile
The main.c file contains the host code for the programming assignment.
The 0_matmul.cl file contains the device code for matrix multiplication without coarsening.
The 1_coarsened_matmul.cl file contains the device code for matrix multiplication with row wise coarsening.
The 2_optional_matmul.cl file contains the device code for matrix multiplication with any optimizations you want that is optional.
There is a Makefile included which compiles it and links it with library helper functions.
It can be run by typing make from the PA3 folder. It generates a solution output file.
During development, make sure to run the make clean command before running make.
How to Test
Use the make naive, make coarsened, and make optional commands to test your respective kernels on the
test cases in the Dataset foldeer.
There are a total of 11 tests on which your program will be evaluated for correctness.
We will use the last test case (testcase 10) to verify if your programs meet the speedup requirements that you should get using coarsening on the row.
Use the make time-naive, make time-coarsened, and make time-optional commands to see timing details for your kernels. Your kernels must produce a time less than 500ms.
For debugging tools, you can use oclgrind, see https://github.com/jrprice/Oclgrind?tab=readme-ov-file#usage for usage documentation
Submission
Submit the main.c, 0_matmul.cl, 1_coarsened_matmul.cl, and 2_optional_matmul.cl, files on gradescope. Preserve the file name while uploading to gradescope.
Gradescope submissions are heavily rate limited starting this PA. See <rate_limit> for more details. Please do not use Gradescope to time your code.
Grading
Part 1: You implement naive matrix multiply without any coarsening for correctness.
Part 2: You will implement coarsened matrix multiply for correctness. You MUST coarsen by row.
Part 3: This is an optional kernel where you will implement matrix multiply using any optimizations from class or outside sources, be creative. This will be timed on a Nvidia 1080 ti and placed on a public gradescope leaderboard showcasing your time. This is NOT graded, bragging rights only.